
Why We Build Knowledge Bases, Not RAG Pipelines - Part 1

How our AI team gives every engineer and every agent access to structured, human-readable knowledge they can actually own, debug, and trust.
Everyone building AI agents eventually hits the same wall: the model doesn't know enough about your systems. The reflexive answer is RAG (Retrieval-Augmented Generation). Embed your docs, stand up a vector database, build a chunking pipeline, and pray that cosine similarity surfaces the right context at inference time.
It works. Sometimes. And then it doesn't, and you're three months into debugging embedding collisions, tuning chunk sizes, experimenting with HyDE and RRF and re-rankers. Building an entire retrieval R&D practice just so your agent can answer questions about your own codebase.
We took a different path. Instead of building smarter retrieval, we built smarter knowledge: structured, indexed, human-readable Markdown that agents pull just-in-time, the same way a developer reads documentation. No vector database. No embedding pipeline. No chunking strategy. Just files.
This is the story of how we got here, what we built, and why we think the industry is overcomplicating this.
The Problem
The Problem With RAG (That Nobody Talks About)
RAG has a marketing problem: it sounds simple. "Just embed your docs and retrieve relevant chunks." In practice, teams discover:
Semantic collapse is real. Your banking API docs for "create account," "close account," and "freeze account" all embed to nearly identical vectors. The retriever can't distinguish them. You start inventing workarounds: metadata filters, hybrid search, HyDE (Hypothetical Document Embeddings), Reciprocal Rank Fusion. Each adds complexity without solving the root cause.
Nobody on your team understands it. Your backend engineers can debug a REST API. They cannot debug why an embedding model maps "transaction decline" and "payment failure" to different regions of a 1536-dimensional space. RAG creates a dependency on ML expertise that most engineering teams don't have and shouldn't need.
The artifacts are opaque. When a RAG-powered agent gives a wrong answer, the debugging experience is: check the retrieval scores, examine which chunks were returned, wonder if the chunking strategy split a critical paragraph across two chunks, consider whether the embedding model handles your domain vocabulary well. Compare this to: open a Markdown file and read it.
It requires dedicated infrastructure. A vector database. An embedding service. A chunking pipeline. An ingestion workflow. Monitoring for embedding drift. This is a second system to operate alongside the one your agents are supposed to help with.
None of this is to say RAG doesn't work. It does, and for certain use cases (massive unstructured corpora, cross-lingual search, zero-shot exploration), it's the right tool. But for engineering teams building agents that operate within known, bounded domains? There's a simpler way.
Phase 1
Compressed Indexes and Just-In-Time Retrieval
The insight came from Vercel's AGENTS.md research: a compressed index that's always loaded in the agent's context outperforms skill-based retrieval (100% vs 79% pass rate). The agent doesn't need to "search" for knowledge. It needs a table of contents and the ability to read specific files.
The Three-Layer Architecture
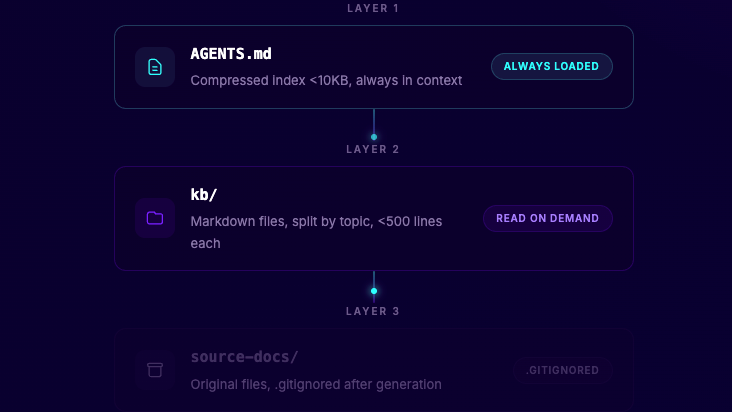
Layer 1: The Compressed Index. A pipe-delimited file that maps every KB entry to a description and tags. Small enough to always fit in context. The agent reads this first, identifies which files are relevant, and reads only those.
Layer 2: The Knowledge Files. Self-contained Markdown files, each under 500 lines, organized by domain. No magic. Just well-structured documentation that any developer can open, read, and edit.
Layer 3: The Source. The original documentation (HTML, PDFs, whatever). Used during KB generation, then .gitignored. The KB files are the source of truth for agents.
How Agents Use It
The agent's workflow mirrors how a human developer works:
- Receive a question or signal (a prompt, an alert, a code review request)
- Scan the compressed index to identify which files are relevant
- Read the specific files
- Reason over them and respond
This is Just-In-Time retrieval. The agent pulls exactly what it needs, when it needs it. No pre-loaded context dump. No noisy chunks from a similarity search. Just precise file reads.
Building the KB
We built a toolkit, agent-kb-generator, that converts source documentation into this structure. It uses a meta-agent that interviews you about your docs, then generates four tailored build-time agents:
The model choices are deliberate. Cheap models for mechanical work. Reasoning models for categorization. A different model family for review, because the converter's biases shouldn't go unchecked.
Side by side
The Same Knowledge, Two Representations
To make this concrete, here's what the same knowledge looks like in both systems:

ⓘ The RAG vectors above represent four different topics. Notice how the values are nearly identical. This is semantic collapse: the embedding model can't meaningfully separate related banking concepts. Your retriever returns all four when you only needed one.
"But what about HyDE, RRF, and re-rankers?"
Fair question. The RAG community has invented increasingly sophisticated retrieval strategies to compensate for the weaknesses above. Here's our take on each:
HyDE (Hypothetical Document Embeddings). The idea: generate a hypothetical answer first, embed that, and use it to retrieve real documents. It helps with vocabulary mismatch, but you're now running two LLM calls per query (one to hallucinate, one to answer), and the quality of retrieval depends on the quality of the hallucination. You've added latency, cost, and a new failure mode. With a JIT index, the agent just reads the file descriptions directly. No hypothetical step needed.
RRF (Reciprocal Rank Fusion). Combines results from multiple retrievers (dense + sparse + keyword) to improve recall. It works, but you're now operating three retrieval systems, each with its own tuning surface. When results are bad, which retriever is at fault? With our approach, there's one index to inspect. One place to fix.
Re-rankers. A second model that re-scores retrieved chunks before passing them to the LLM. This adds another model to host, another latency hop, and another component to monitor. It's an admission that the first retrieval wasn't good enough. We'd rather make the first lookup precise by investing in index quality (a human-readable, editable artifact) than bolt on a second model to fix the first.
Metadata filtering. Attaching structured metadata to chunks so you can filter by document type, date, or section. This is the closest to our approach, and it's telling: the most effective RAG improvement is the one that adds human-authored structure on top of embeddings. We just skip the embeddings entirely and go straight to the structure.
Each of these techniques makes RAG better. None of them make it simpler. Every one adds infrastructure, latency, cost, and debugging surface area. For teams operating in bounded domains where the knowledge is curated and well-structured, you can sidestep all of it.
Up Next
Part 2: From Static Docs to Living Knowledge
Architecture is only as good as its freshness. A perfect knowledge base that nobody updates is just a prettier graveyard.
In Part 2, we'll show how we turned knowledge contribution into a one-line command, how CI does the synthesis work so humans don't have to, and why the update pipeline matters more than the retrieval pipeline. We'll also cover how we package and distribute knowledge across teams without a single vector database in sight.
Because the hardest problem was never retrieval. It was getting people to contribute.
Start building a better bank

